Resources for all things related to anti-car dependency
Published on 19 May 2022
Ever need to find some articles, studies, videos, local advocacy groups, subreddits, twitter, books, podcasts to support anti-car dependency? This is your one stop shop for everything.
Demo Jump to heading
Link: https://silly-archimedes-134f9f.netlify.app
Motivation Jump to heading
I created this site to contain all things related to anti-car dependency. Having a discussion on how cars are bad for the city? Just look it up. Want to know what makes a good bike infrastructure? Just look it up.
Tech stack Jump to heading
When I was starting this project, I was very motivated to look up each post in the /r/fuckcars subreddit and search for articles, videos, etc. But it was all too time-consuming. So I wrote a piece of software in Elixir where it would look up the top posts of the day in the subreddit and recursively find any links in the comments. I used Phoenix and Phoenix Liveview to build the UI, tailwind and daisyui for styling, AnimXYZ for animations and Postgres for the database.
From there, it's reviewing time and see if it is appropriate to be added to my site. Then, I'll put it into my CMS, Emacs Org Mode and into the appropriate section. I also like to save the reddittor's comment link (I like to keep it for context). Most of the time, I'll add some words of my own into each entry or put quotes for the article so that people don't have to read the entire thing to understand the gist of it.
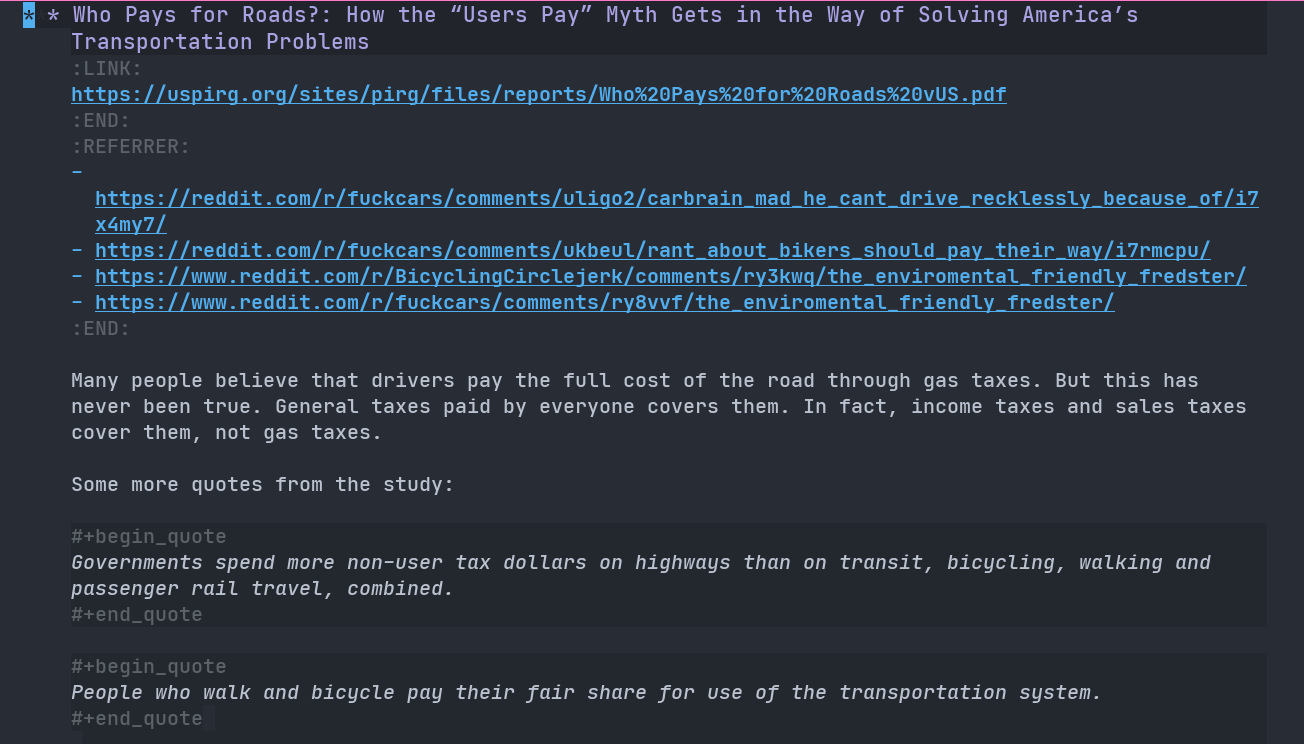
Lately I've found that this method of saving links is not sustainable in a way that multiple sections are also referencing the same article. To combat this, I saved those links into Zotero and the Better Bibtex plugin so that it will automatically sync to my org files. I used the org-ref plugin to add citations to my knowledge base.
Once I'm happy with it, it's time to build the website. I used ox-hugo to export them to a Hugo compatible markdown file. Then, I'll use Netlify to deploy. The entries with the citations is slower to export because it has to cross reference with the bibliography but nothing too bad. I've connected Netlify to my Github repo so it will automatically deploy when I push changes to the master branch. Since it's all static files, I don't have to keep a server running. Netlify handles them all for me.


Remember the reddittor's comment link that I saved earlier? I used that to thank the person for providing me the link as well as promoting my site to them. To help create this thank you message, I used QMK dynamic macros.
Reasons for choosing Elixir Jump to heading
I've always wanted to learn Elixir so I thought this would be a good chance to do so. What I did is get the top 100 posts of the day in /r/fuckcars via the Reddit API. For each of this post, I have to call the Reddit API again to get the comments. I used Task.async and Task.await_many to do this. For each of the comment API results, I traverse the comment thread recursively to find any links via regex.
There are some special cases though. One example is bots posting links which I don't find useful. To handle this, I have a list of bot names that I would check against. If it matches, I don't save it into my database.
Aonother case is people posting links that I've already seen a lot. For example, Not Just Bikes videos are often posted in the comments. I handle this the same way as I handle the bots; by keeping a list of URLs that I don't want to save in my database.
Reasons for choosing Org Mode Jump to heading
This is the only piece of technology that I wouldn't part with. Storing a knowledge base is so much easier in org-mode than anything else I've ever used. It can be extended with my own custom functions. There are third party libraries written by the community to assist me. It has support for vim key bindings via evil which made traversing text very quick.
Reasons for choosing Hugo Jump to heading
Because of my dependency of Org Mode, ox-hugo is the easiest solution for me without having to build my own custom parser. You can use ox-md to export your files into markdown but then you'd miss out on things like short codes where ox-hugo has support for. There's also a good Hugo theme called Relearn which suited my needs.
Reasons for choosing Netlify Jump to heading
Netlify has first class support for Hugo so it's a pretty easy decision for me. Plus, I have experience with deploying on Netlify before.
Features for the crawler Jump to heading
Undo button Jump to heading
Sometimes I would accidentally delete a link. I had to run an UPDATE command in Postgres in order to undo them. This happened so many times that I created a button for it.
Notifications Jump to heading
Elixir has built in alerts in the form of put_flash. But I felt like it's not cool enough. I wanted a notification that stacks on top of one another. I combined Phoenix.LiveView.JS to trigger the Anim.XYZ classes to achieve this. I used to use Alpine.JS to do this but I couldn't make it work.
Reddit embeds Jump to heading
Previously, I've sorted the comments based on descending order of the Postgres comment id. But it was not a really good experience having comments of the same post showing up in different places. To solve this, I've grouped up the comments by their post id. For each of the post id, I called a service to return a Reddit embed.
def get_embed(id) do
body =
with {:post_state, post_state} <- {:post_state, PostState.get_by_post_id(id)},
{:body, body} <- {:body, Map.get(post_state, "body")} do
body
else
_ ->
{:ok, %{body: body}} =
get("https://www.redditmedia.com/r/fuckcars/comments/" <> id <> "?embed=true")
body
end
endHere is what it looks like:
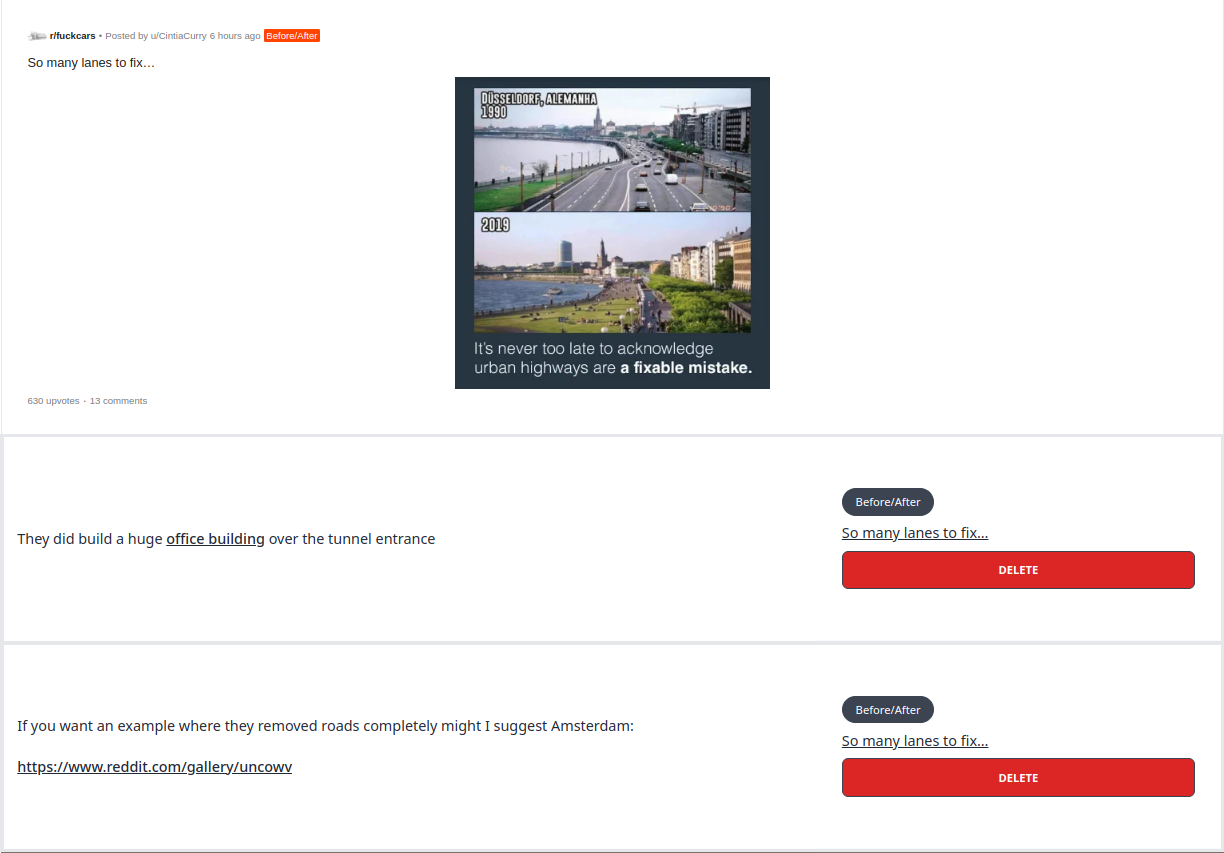
Automatic crawling Jump to heading
If you see in the demo video, I had to press the trigger crawler button in order for it to do it's thing. I thought that I could optimize this process by running it via a scheduler e.g. Elixir's cron like scheduler or Oban. But the bottleneck of this project is me because I have to review each of these links. I don't want to face long list of links each day and a longer list the next day. It would be very disheartening. So I went with a pull based approach rather than a push based approach instead.
I got permabanned from /r/fuckcars for spamming Jump to heading
Remember the thank you message I wrote acknowledging the reddittors for the links? Because my messages are too similar and too recent to one another, I got banned and had to request to be unbanned. Since then, I learned not to batch my work. Every time I found a link, I would run the export and publish it immediately.